

The DEVONtechnologies Blog
Using Local AI in DEVONthink?
When it comes to AI in DEVONthink 4, questions of privacy and cost usually come up. At this time, using a commercial service will provide the best and most consistent results. Alternatively, you can use smaller AI models that run locally on your Mac. Unlike the large, commercial models, many of these models are free and the query is processed locally rather than running on a third-party server. However, there are also some caveats. Here we give you an overview of local AI models in DEVONthink.
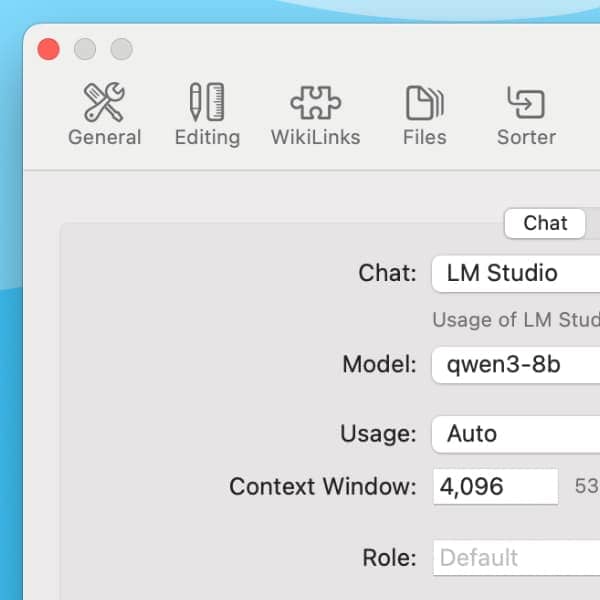
In DEVONthink’s AI > Chat settings, you can define an AI provider and a model. In the Chat setting, in addition to the well-known commercial manufacturers such as ChatGTP or Claude, you can select local AI platforms in the lower section. These platforms allow you to run AI models locally on your Mac. At the time of this post, the local options are:
- Ollama: This is an open-source platform that allows you to run local AI models you download. Though simple to download and run, it requires use of the Terminal to install large language models. On this quickstart page, you will see a list of many popular models. However, you should use the
pullcommand, e.g.,ollama pull gemma3:8b, to install and run the model locally. - GPT4All: This application lets you easily download local AI models and chat with them. You can also run a server so DEVONthink 4 can use it for its AI-related features. Just click the checkbox in GPT4All’s Settings > Enable Local API Server.
- LM Studio: Similar to GPT4All, you have a nice interface for general chatting outside our application. It also has a server built in and can power AI chat in DEVONthink. You can enable it in the Developer settings by enabling the server and loading a model.
While local AI is certainly more private, you do need to be aware of some limitations.
- Hallucinations are nonsense or irrelevant replies from AI. Though larger commercial models can hallucinate, they are much better at staying on track due to the massive volume of parameters they access. Local models almost always work with a small fraction of data so can more easily return unexpected results.
- Hardware will be a severely limiting factor for many machines. The more RAM a machine has, the larger the model it can run; the recommended model will generally be 50 to 75% of the total available RAM. For example, a Mac with 16GB RAM will run a model with a maximum of 12 billion parameters. While that may sound like a lot, it’s actually a small model. The larger, most powerful models have hundreds of billions of parameters.
- Some models may be able to answer chat questions but aren’t able to accept commands, called tool calls. So it may be able to create a response but not necessarily turn it into a new document.
Even given the limitations, running a local LLM can certainly provide some useful results and be fun to explore as the technologies evolve! Local models are also an interesting option for anyone who prefers not to have their requests run via a third-party server for privacy reasons. Also, check out the Getting Started > AI Explained section of the built-in Help and user handbook for an overview of the AI integration of DEVONthink.